Road 2 NLP- Word Embedding词向量(ELMo)
1. 参考资料
- ELMo论文:《Deep contextualized word representations》,作者Matthew et al. ,AllenNLP
- ELMo前论文(ELMo基于该论文模型改进):《Semi-supervised sequence tagging with bidirectional language models》
- 知乎专栏文《ELMo原理解析及简单上手使用》
2. RNN基础:标准RNN/LSTM/GRU
ELMo基于双向LSTM,因此在此之前先了解下常用RNN结构,顺便了解RNN结构。
ELMo中的常用RNN结构:LSTM & GRU(均为标准RNN的变体)。
2.1 标准RNN(Recurrent Neural Networks)
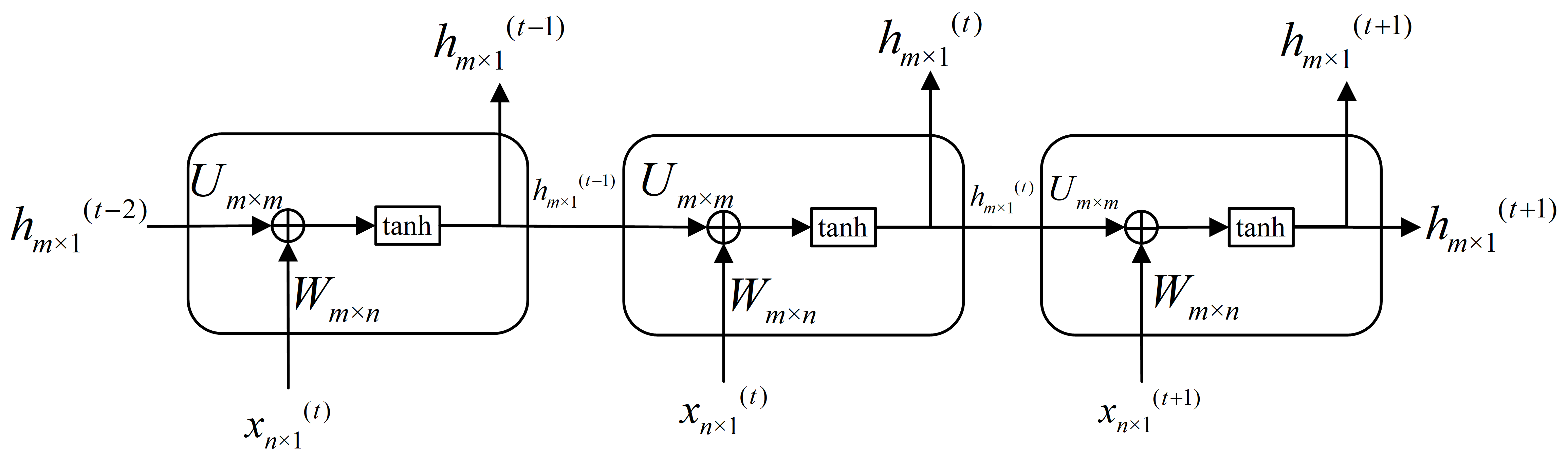
如上图,符号说明:$(t)、(t-1)$表示时序,即对应句子分词后词语的词向量;$h_{m×1}$为隐状态;$x_{n×1}$为词向量;$W_{m×n}、U_{m×m}$分别为系数矩阵,初值随机化;$h_{m×1}^{(0)}$初值随机化。注意,$W_{m×n}、U_{m×m}$矩阵共享,不因时序而不同。
因此,标准RNN隐状态更新公式为
其中,$f(X)=tanh(X)$。
标准RNN存在梯度消失问题。单个RNN cell的参数量:$mn+mm+m$,包括$W_{m×n}、U_{m×m}、b_{m×1}$;$h_{m×1}$是生成的,不算入参数。
2.2 LSTM(Long Short-Term Memory)
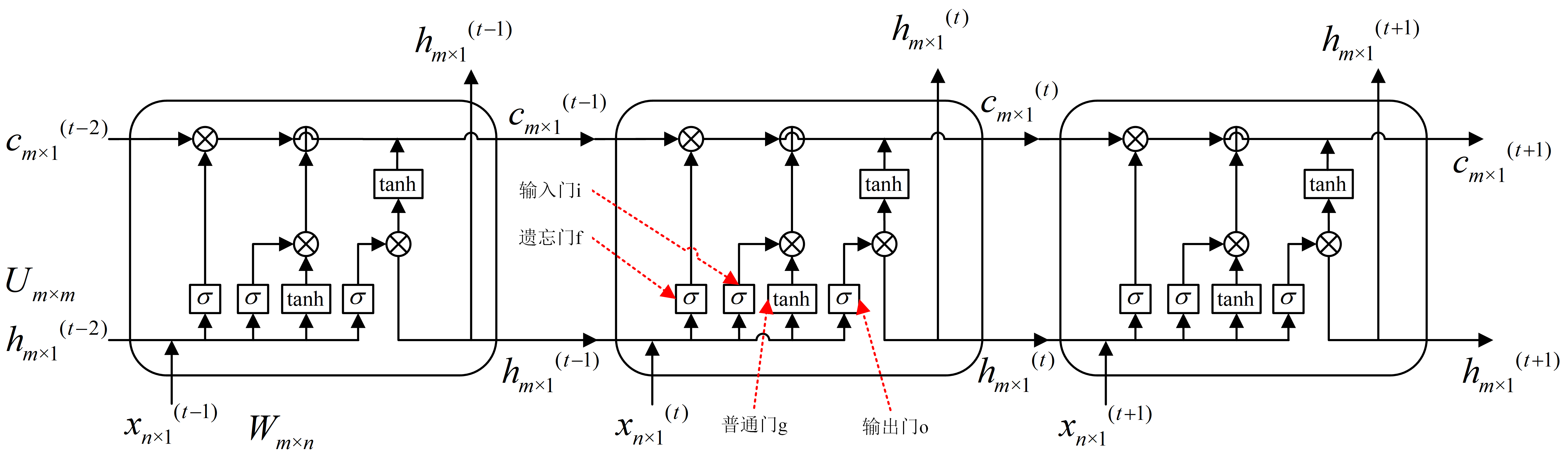
LSTM(Long Short-Term Memory),属于标准RNN变体,当前时刻状态可受前面几个时刻的影响。公式如下:
PS:注意上述式子中c、h的乘法均为,按对应位的元素相乘,即$a_{m×1} \cdot b_{m×1} = c_{m×1}$。其中,$\sigma(x)= \frac{1}{1+e^{-x}}$,是sigmoid函数,此处为按点求$\sigma(x)$。
单个LSTM cell的参数量:$4(mn+mm+m)$,包括4组$W_{m×n}、U_{m×m}、b_{m×1}$。符号说明和标准RNN一致。
2.3 GRU(Gated Recurrent Unit)
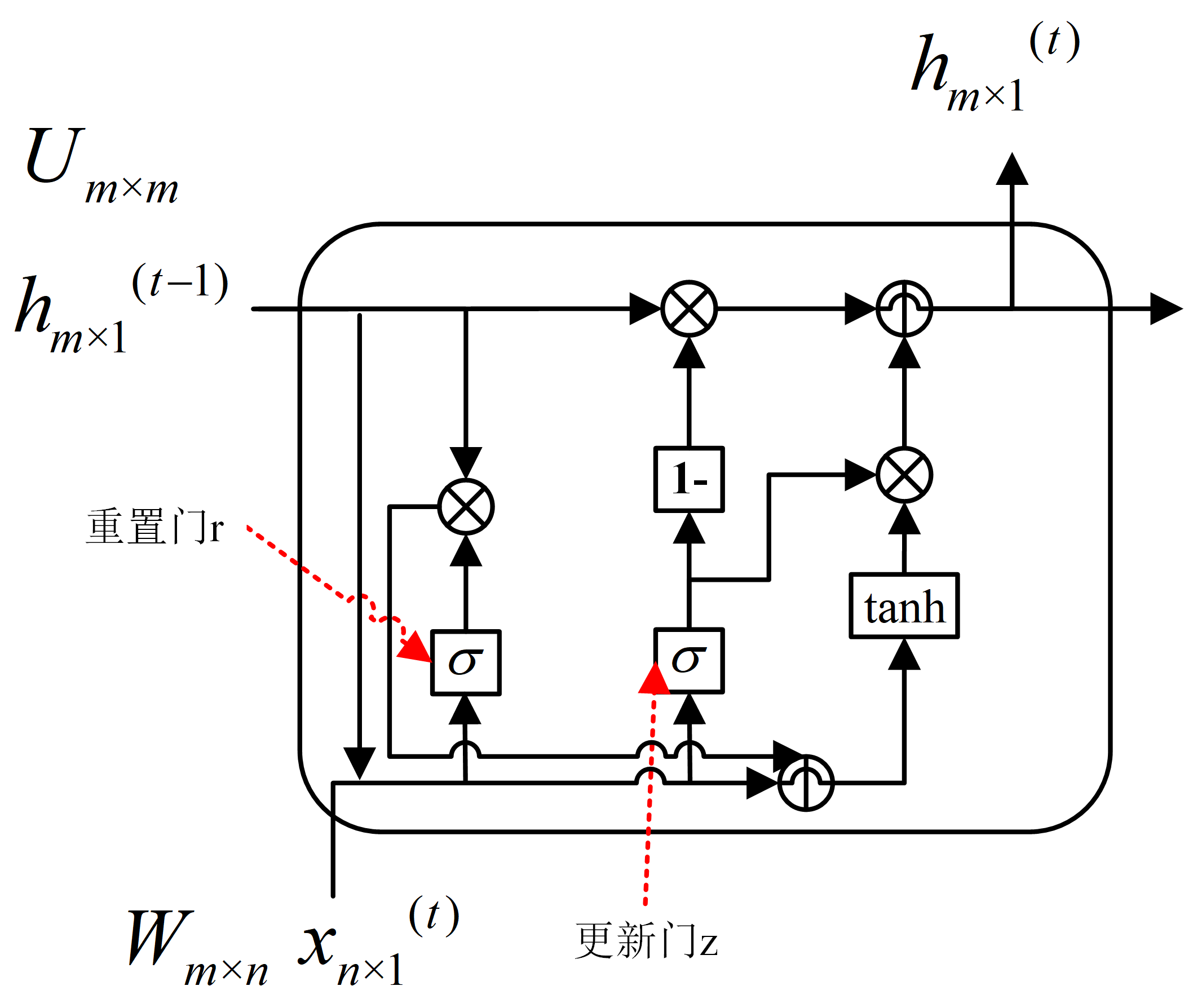
可以看出,GRU其实是LSTM变体,简单版LSTM。符号说明和标准RNN一致。
3. ELMo(Embeddings from Language Models)
ELMo框架如下(LSTM可换GRU):
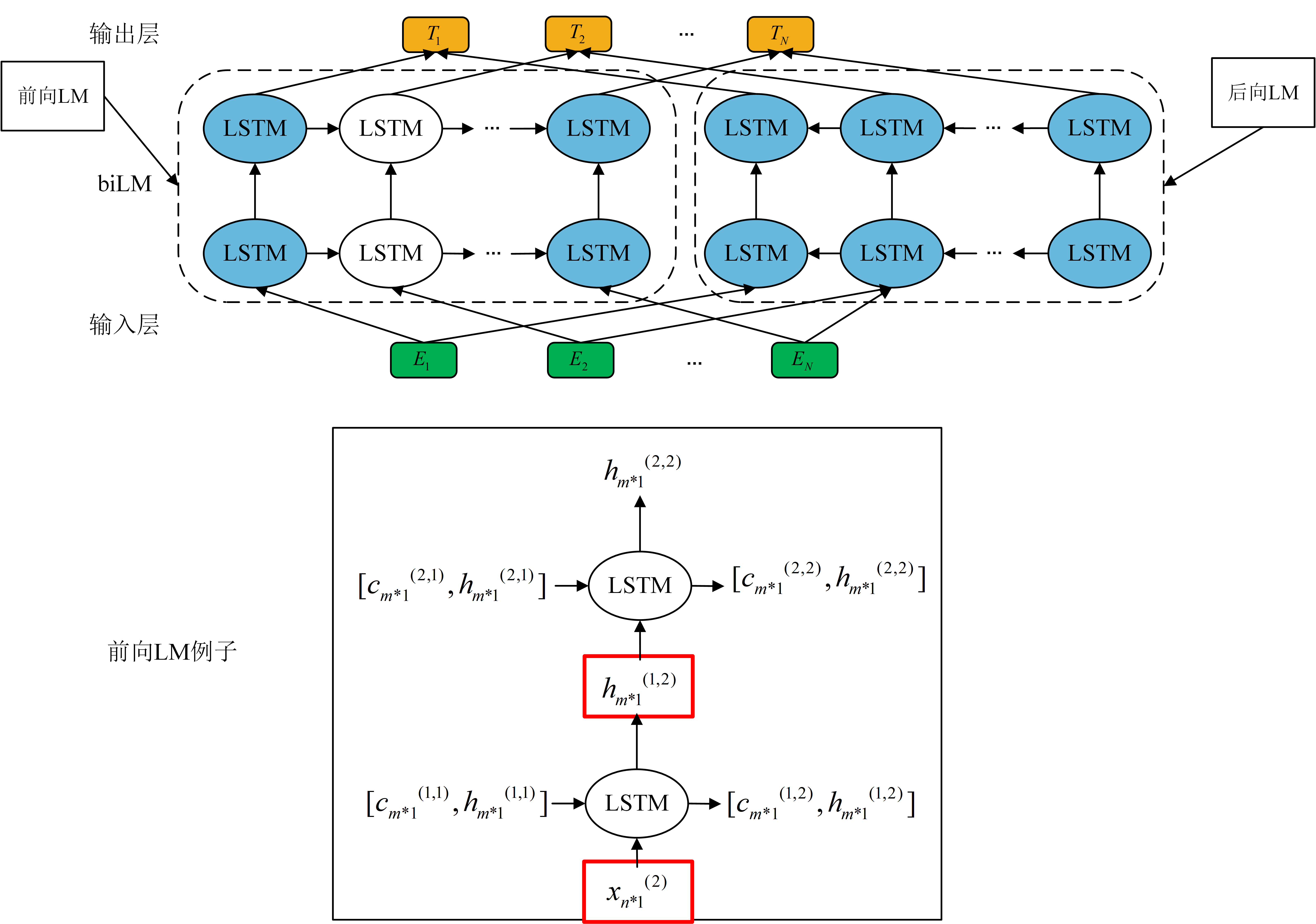
ELMo包含1个biLM(Bidirectional Language Models,即双向语言模型),分别是前向预测和后向预测。
即ELMo目标函数为biLM对数似然函数。
观察ELMo网络可知,以上图2层LSTM为例。分析如下:
注意:底层$E_{i}(i=1,2,…)$输入,为句子分词后对应位置单词的静态词向量,常用Word2vec/GloVe等。词向量维度为n
记下层为层1,上层为层2。
- 注意:1层LSTM包括前向LM & 后向LM,且二者cell数目一致,等于词语数目。设词语数为A,则1层LSTM cell数目 = 2*A。
- 以上图第二个词语,即$E_{2}$处,的前向LM为例,有上图所示。观察可以发现,其实在层2的下侧输入中,标准LSTM输入应该为$x_{n×1}$,即n维向量。然而!又由于LSTM隐状态输出为$h_{m×1}$,即m维向量!!因此,不难推断出,biLM中,其实是取m = n了!!
- 如何获得ELMo词向量:
loss function为biLM对数似然函数,常规用SGD等算法优化更新参数;
ELMo词向量获取方法有多种:
注意: $T_{2}$ 为前向 & 后向LM concat向量,其余$T_{i}$ 同理,维度为2m
(1) 只取顶层LSTM的输出隐状态h向量(该例子即为层2)
以该例子(2层LSTM)中单词$E_{2}$为例,其对应ELMo词向量为
即将该单词原输入词向量$x_{2}$和对应LSTM cell输出隐状态$T_{2}$,直接拼接。由于m = n,则ELMo词向量维度为3m。e.g.,取Word2vec维度为300输入,则ELMo输出为900维度词向量。
即下图的右侧图,左侧不用管。来源:《Semi-supervised sequence tagging with bidirectional language models》

(2) 取所有层的LSTM的输出隐状态h向量(层数设为L)
在这方法中,又有2种思路:1- 直接concat;2- 带系数求和后concat
1- 直接concat
同上,以该例子(2层LSTM)中单词$E_{2}$为例,此思路的对应ELMo词向量为:
和方法1相比,方法2也就只是concat多1层h向量。然而,在这例子是多1层,当层数很大时,例如100,则是concat多99层。
该方法下ELMo词向量维度和LSTM层数有关,为(m+2mL)维度
2- 带系数求和后concat
同上,有该思路下,单词$E_{2}$ELMo词向量:
$$
ELMo_{E2}=γ\sum_{j=0}^{L}{s^{(j,2)} \cdot h_{m×1}^{(j,2)}} \\ T_{2}^{‘} = concat(ELMo_{E2}^{前向LM}, ELMo_{E2}^{后向LM})\\ ELMo_E2_method3 = concat(x_{2},T_{2}^{‘})
$$
该思路关键如下:给每一层LSTM一个系数向量$s_{2A×1}$,按位置和该层的2A个$h$向量相乘后,所有层求和。最后再乘上系数γ,作为向量$ELMO_{E}$。注意:$ELMO_{E}$维度为m,还需一步是对应位置的前后向LM concat为$T_{2}^{‘}$,维度为2m。然后,将原输入静态词向量$x$和$T_{2}^{‘}$concat。该方法下ELMo词向量维度,为3m维度
论文采取方式:方法3,带系数求和后concat。其实方法2也可以,直接concat所有层h,但可能维度过高了。